最大流
本页面主要介绍最大流问题相关的算法知识。
概述
网络流基本概念参见 网络流简介。
令
Ford-Fulkerson 增广
Ford-Fulkerson 增广是计算最大流的一类算法的总称。该方法运用贪心的思想,通过寻找增广路来更新并求解最大流。
概述
给定网络
对于边
我们将
正如我们马上要提到的,流量可能是负值,因此,
我们将
在最大流算法的代码实现中,我们往往需要支持快速访问反向边的操作。在邻接矩阵中,这一操作是 trivial 的(
初次接触这一方法的读者可能察觉到一个违反直觉的情形——反向边的流量
以下案例有可能帮助你理解这一过程。假设假设
- 我们注意到,如果进行中图上的增广,这个局部的最大流量不是
- 现在引入退流操作。第一次增广后,退流意味着
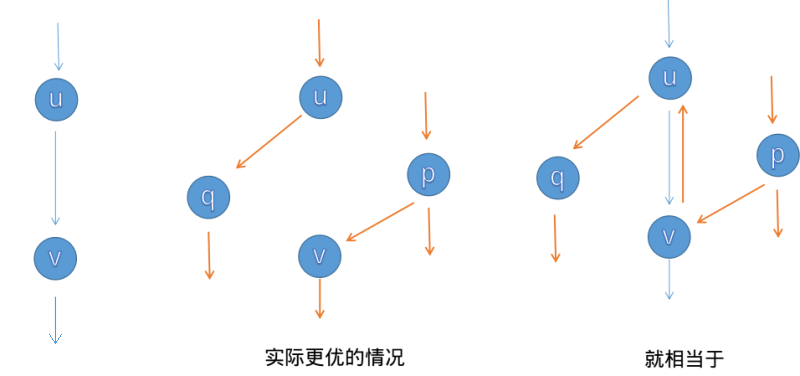
以上案例告诉我们,退流操作带来的「抵消」效果使得我们无需担心我们按照「错误」的顺序选择了增广路。
容易发现,只要
如果你希望严格证明 Ford-Fulkerson 增广的正确性,请参考 最大流最小割定理。
在整数流量的网络
对于 Ford-Fulkerson 增广的不同实现,时间复杂度也各不相同。其中较主流的实现有 Edmonds-Karp, Dinic, SAP, ISAP 等算法,我们将在下文中分别介绍。
Edmonds-Karp 算法
算法思想
如何在
-
如果在
-
对于增广路
-
因为我们修改了流量,所以我们得到新的
以上算法即 Edmonds-Karp 算法。
时间复杂度分析
接下来让我们尝试分析 Edmonds-Karp 算法的时间复杂度。
显然,单轮 BFS 增广的时间复杂度是
增广总轮数的上界是
首先,我们引入一个引理——最短路非递减引理。具体地,我们记
不妨称增广路上剩余容量最小的边是饱和边(存在多条边同时最小则取任一)。如果一条有向边
在
接下来我们证明最短路非递减引理,即
考虑反证。对于某一轮增广,我们假设存在若干结点,它们在该轮增广后到
在 $G_{f'}$ 中 $s$ 到 $v$ 的最短路上,我们记 $u$ 是 $v$ 的上一个结点,即 $d_{f'}(u) + 1 = d_{f'}(v)$。
为了不让 $u$ 破坏 $v$ 的「距离最小」这一性质,$u$ 必须满足 $d_{f'}(u) \geq d_f(u)$。
对于上式,我们令不等号两侧同加,得 $d_{f'}(v) \geq d_f(u) + 1$。根据反证假设进行放缩,我们得到 $d_f(v) > d_f(u) + 1$。
以下我们尝试讨论 $(u, v)$ 上的增广方向。
- 假设有向边 $(u, v) \in E_f$。根据 BFS「广度优先」的性质,我们有 $d_f(u) + 1 \geq d_f(v)$。该式与放缩结果冲突,导出矛盾。
- 假设有向边 $(u, v) \not \in E_f$。根据 $u$ 的定义我们已知 $(u, v) \in E_{f'}$,因此这条边的存在必须是当前轮次的增广经过了 $(v, u)$ 并退流产生反向边的结果,也即 $d_f(v) + 1 = d_f(u)$。该式与放缩结果冲突,导出矛盾。
由于 $(u, v)$ 沿任何方向增广都会导出矛盾,我们知道反证假设不成立,最短路非递减引理得证。将单轮 BFS 增广的复杂度与增广轮数的上界相乘,我们得到 Edmonds-Karp 算法的时间复杂度是
代码实现
Edmonds-Karp 算法的可能实现如下。
#define maxn 250
#define INF 0x3f3f3f3f
struct Edge {
int from, to, cap, flow;
Edge(int u, int v, int c, int f) : from(u), to(v), cap(c), flow(f) {}
};
struct EK {
int n, m; // n:点数,m:边数
vector<Edge> edges; // edges:所有边的集合
vector<int> G[maxn]; // G:点 x -> x 的所有边在 edges 中的下标
int a[maxn], p[maxn]; // a:点 x -> BFS 过程中最近接近点 x 的边给它的最大流
// p:点 x -> BFS 过程中最近接近点 x 的边
void init(int n) {
for (int i = 0; i < n; i++) G[i].clear();
edges.clear();
}
void AddEdge(int from, int to, int cap) {
edges.push_back(Edge(from, to, cap, 0));
edges.push_back(Edge(to, from, 0, 0));
m = edges.size();
G[from].push_back(m - 2);
G[to].push_back(m - 1);
}
int Maxflow(int s, int t) {
int flow = 0;
for (;;) {
memset(a, 0, sizeof(a));
queue<int> Q;
Q.push(s);
a[s] = INF;
while (!Q.empty()) {
int x = Q.front();
Q.pop();
for (int i = 0; i < G[x].size(); i++) { // 遍历以 x 作为起点的边
Edge& e = edges[G[x][i]];
if (!a[e.to] && e.cap > e.flow) {
p[e.to] = G[x][i]; // G[x][i] 是最近接近点 e.to 的边
a[e.to] =
min(a[x], e.cap - e.flow); // 最近接近点 e.to 的边赋给它的流
Q.push(e.to);
}
}
if (a[t]) break; // 如果汇点接受到了流,就退出 BFS
}
if (!a[t])
break; // 如果汇点没有接受到流,说明源点和汇点不在同一个连通分量上
for (int u = t; u != s;
u = edges[p[u]].from) { // 通过 u 追寻 BFS 过程中 s -> t 的路径
edges[p[u]].flow += a[t]; // 增加路径上边的 flow 值
edges[p[u] ^ 1].flow -= a[t]; // 减小反向路径的 flow 值
}
flow += a[t];
}
return flow;
}
};Dinic 算法
算法思想
考虑在增广前先对
如果我们在层次图
尽管在上文中我们仅在单条增广路上定义了增广/增广流,广义地,「增广」一词不仅可以用于单条路径上的增广流,也可以用于若干增广流的并——后者才是我们定义阻塞流时使用的意义。
定义层次图和阻塞流后,Dinic 算法的流程如下。
- 在
- 在
- 将
- 重复以上过程直到不存在从
此时的
在分析这一算法的复杂度之前,我们需要特别说明「在
注意到在
多路增广是 Dinic 算法的一个常数优化——如果我们在层次图上找到了一条从
可能是由于大量网络资料的错误表述引发以讹传讹的情形,相当数量的选手喜欢将当前弧优化和多路增广并列称为 Dinic 算法的两种优化。实际上,当前弧优化是用于保证 Dinic 时间复杂度正确性的一部分,而多路增广只是一个不影响复杂度的常数优化。
时间复杂度分析
应用当前弧优化后,对 Dinic 算法的时间复杂度分析如下。
首先,我们尝试证明单轮增广中 DFS 求阻塞流的时间复杂度是
考虑阻塞流
每找到一条增广路就有一条饱和边消失(剩余容量清零)。考虑阻塞流
此外,对于沿当前弧跳转但由于某个位置阻塞所以没有成功得到增广路的情形,我们将这些不完整的路径上的最后一条边形成的边集记作
由于
对于每个结点,我们维护下一条可以增广的边,而当前弧最多变化
「当前弧最多变化
注意到层次图的层数显然不可能超过
我们需要引入预流推进类算法(另一类最大流算法)中的一个概念——高度标号。为了更方便地结合高度标号表述我们的证明,在证明过程中,我们令
我们给高度标号一个不严格的临时定义——在网络
考察所有
-
-
以上观察让我们得出一个结论——
现在,对于一条
考虑反证,我们假设
令
-
-
由于我们无论以何种方式满足断言均得到
考虑反证。假设层次图的层数在一轮增广结束后较原先相等,则层次图上应仍存在至少一条从
「一轮增广结束后新的层次图上
将单轮增广的时间复杂度
如果需要令 Dinic 算法的实际运行时间接近其理论上界,我们需要构造有特殊性质的网络作为输入。由于在算法竞赛实践中,对于网络流知识相关的考察常侧重于将原问题建模为网络流问题的技巧。此时,我们的建模通常不包含令 Dinic 算法执行缓慢的特殊性质;恰恰相反,Dinic 算法在大部分图上效率非常优秀。因此,网络流问题的数据范围通常较大,「将
特殊情形下的时间复杂度分析
在一些性质良好的图上,Dinic 算法有更好的时间复杂度。
对于网络
在单位容量的网络中,Dinic 算法的单轮增广的时间复杂度为
这是因为,每次增广都会导致增广路上的所有边均饱和并消失,故单轮增广中每条边只能被增广一次。
在单位容量的网络中,Dinic 算法的增广轮数是
以源点
假设我们已经进行了
在单位容量的网络中,Dinic 算法的增广轮数是
假设我们已经进行了
为最大化
在单位容量的网络中,如果除源汇点外每个结点
我们引入以下引理——对于这一形式的网络,其上的任意流总是可以分解成若干条单位流量的、点不交 的增广路。
假设我们已经进行了
考虑
综上,我们得出一些推论。
- 在单位容量的网络上,Dinic 算法的总时间复杂度是
- 在单位容量的网络上,如果除源汇点外每个结点
代码实现
struct MF {
struct edge {
int v, nxt, cap, flow;
} e[N];
int fir[N], cnt = 0;
int n, S, T;
ll maxflow = 0;
int dep[N], cur[N];
void init() {
memset(fir, -1, sizeof fir);
cnt = 0;
}
void addedge(int u, int v, int w) {
e[cnt] = {v, fir[u], w, 0};
fir[u] = cnt++;
e[cnt] = {u, fir[v], 0, 0};
fir[v] = cnt++;
}
bool bfs() {
queue<int> q;
memset(dep, 0, sizeof(int) * (n + 1));
dep[S] = 1;
q.push(S);
while (q.size()) {
int u = q.front();
q.pop();
for (int i = fir[u]; ~i; i = e[i].nxt) {
int v = e[i].v;
if ((!dep[v]) && (e[i].cap > e[i].flow)) {
dep[v] = dep[u] + 1;
q.push(v);
}
}
}
return dep[T];
}
int dfs(int u, int flow) {
if ((u == T) || (!flow)) return flow;
int ret = 0;
for (int& i = cur[u]; ~i; i = e[i].nxt) {
int v = e[i].v, d;
if ((dep[v] == dep[u] + 1) &&
(d = dfs(v, min(flow - ret, e[i].cap - e[i].flow)))) {
ret += d;
e[i].flow += d;
e[i ^ 1].flow -= d;
if (ret == flow) return ret;
}
}
return ret;
}
void dinic() {
while (bfs()) {
memcpy(cur, fir, sizeof(int) * (n + 1));
maxflow += dfs(S, INF);
}
}
} mf;MPM 算法
MPM(Malhotra, Pramodh-Kumar and Maheshwari) 算法得到最大流的方式有两种:使用基于堆的优先队列,时间复杂度为
MPM 算法的整体结构和 Dinic 算法类似,也是分阶段运行的。在每个阶段,在
MPM 算法需要考虑顶点而不是边的容量。在分层网络
我们称节点
时间复杂度分析
MPM 算法的每个阶段都需要
阶段总数小于 V 的证明
MPM 算法在少于
引理 1:每次迭代后,从
证明:固定一个阶段
引理 2:
证明:从引理一我们得出,
实现
struct MPM {
struct FlowEdge {
int v, u;
long long cap, flow;
FlowEdge() {}
FlowEdge(int _v, int _u, long long _cap, long long _flow)
: v(_v), u(_u), cap(_cap), flow(_flow) {}
FlowEdge(int _v, int _u, long long _cap)
: v(_v), u(_u), cap(_cap), flow(0ll) {}
};
const long long flow_inf = 1e18;
vector<FlowEdge> edges;
vector<char> alive;
vector<long long> pin, pout;
vector<list<int> > in, out;
vector<vector<int> > adj;
vector<long long> ex;
int n, m = 0;
int s, t;
vector<int> level;
vector<int> q;
int qh, qt;
void resize(int _n) {
n = _n;
ex.resize(n);
q.resize(n);
pin.resize(n);
pout.resize(n);
adj.resize(n);
level.resize(n);
in.resize(n);
out.resize(n);
}
MPM() {}
MPM(int _n, int _s, int _t) {
resize(_n);
s = _s;
t = _t;
}
void add_edge(int v, int u, long long cap) {
edges.push_back(FlowEdge(v, u, cap));
edges.push_back(FlowEdge(u, v, 0));
adj[v].push_back(m);
adj[u].push_back(m + 1);
m += 2;
}
bool bfs() {
while (qh < qt) {
int v = q[qh++];
for (int id : adj[v]) {
if (edges[id].cap - edges[id].flow < 1) continue;
if (level[edges[id].u] != -1) continue;
level[edges[id].u] = level[v] + 1;
q[qt++] = edges[id].u;
}
}
return level[t] != -1;
}
long long pot(int v) { return min(pin[v], pout[v]); }
void remove_node(int v) {
for (int i : in[v]) {
int u = edges[i].v;
auto it = find(out[u].begin(), out[u].end(), i);
out[u].erase(it);
pout[u] -= edges[i].cap - edges[i].flow;
}
for (int i : out[v]) {
int u = edges[i].u;
auto it = find(in[u].begin(), in[u].end(), i);
in[u].erase(it);
pin[u] -= edges[i].cap - edges[i].flow;
}
}
void push(int from, int to, long long f, bool forw) {
qh = qt = 0;
ex.assign(n, 0);
ex[from] = f;
q[qt++] = from;
while (qh < qt) {
int v = q[qh++];
if (v == to) break;
long long must = ex[v];
auto it = forw ? out[v].begin() : in[v].begin();
while (true) {
int u = forw ? edges[*it].u : edges[*it].v;
long long pushed = min(must, edges[*it].cap - edges[*it].flow);
if (pushed == 0) break;
if (forw) {
pout[v] -= pushed;
pin[u] -= pushed;
} else {
pin[v] -= pushed;
pout[u] -= pushed;
}
if (ex[u] == 0) q[qt++] = u;
ex[u] += pushed;
edges[*it].flow += pushed;
edges[(*it) ^ 1].flow -= pushed;
must -= pushed;
if (edges[*it].cap - edges[*it].flow == 0) {
auto jt = it;
++jt;
if (forw) {
in[u].erase(find(in[u].begin(), in[u].end(), *it));
out[v].erase(it);
} else {
out[u].erase(find(out[u].begin(), out[u].end(), *it));
in[v].erase(it);
}
it = jt;
} else
break;
if (!must) break;
}
}
}
long long flow() {
long long ans = 0;
while (true) {
pin.assign(n, 0);
pout.assign(n, 0);
level.assign(n, -1);
alive.assign(n, true);
level[s] = 0;
qh = 0;
qt = 1;
q[0] = s;
if (!bfs()) break;
for (int i = 0; i < n; i++) {
out[i].clear();
in[i].clear();
}
for (int i = 0; i < m; i++) {
if (edges[i].cap - edges[i].flow == 0) continue;
int v = edges[i].v, u = edges[i].u;
if (level[v] + 1 == level[u] && (level[u] < level[t] || u == t)) {
in[u].push_back(i);
out[v].push_back(i);
pin[u] += edges[i].cap - edges[i].flow;
pout[v] += edges[i].cap - edges[i].flow;
}
}
pin[s] = pout[t] = flow_inf;
while (true) {
int v = -1;
for (int i = 0; i < n; i++) {
if (!alive[i]) continue;
if (v == -1 || pot(i) < pot(v)) v = i;
}
if (v == -1) break;
if (pot(v) == 0) {
alive[v] = false;
remove_node(v);
continue;
}
long long f = pot(v);
ans += f;
push(v, s, f, false);
push(v, t, f, true);
alive[v] = false;
remove_node(v);
}
}
return ans;
}
};ISAP
在 Dinic 算法中,我们每次求完增广路后都要跑 BFS 来分层,有没有更高效的方法呢?
答案就是下面要介绍的 ISAP 算法。
过程
和 Dinic 算法一样,我们还是先跑 BFS 对图上的点进行分层,不过与 Dinic 略有不同的是,我们选择在反图上,从
执行完分层过程后,我们通过 DFS 来找增广路。
增广的过程和 Dinic 类似,我们只选择比当前点层数少
与 Dinic 不同的是,我们并不会重跑 BFS 来对图上的点重新分层,而是在增广的过程中就完成重分层过程。
具体来说,设
容易发现,当
和 Dinic 类似,ISAP 中也存在 当前弧优化。
而 ISAP 还存在另外一个优化,我们记录层数为
实现
Push-Relabel 预流推进算法
该方法在求解过程中忽略流守恒性,并每次对一个结点更新信息,以求解最大流。
通用的预流推进算法
首先我们介绍预流推进算法的主要思想,以及一个可行的暴力实现算法。
预流推进算法通过对单个结点的更新操作,直到没有结点需要更新来求解最大流。
算法过程维护的流函数不一定保持流守恒性,对于一个结点,我们允许进入结点的流超过流出结点的流,超过的部分被称为结点
若
预流推进算法维护每个结点的高度
高度函数2
准确地说,预流推进维护以下的一个映射
称
引理 1:设
算法只会在
推送(Push)
适用条件:结点
于是,我们尽可能将超额流从
如果
重贴标签(Relabel)
适用条件:如果结点
则将
初始化
上述将
过程
我们每次扫描整个图,只要存在结点
如图,每个结点中间表示编号,左下表示高度值
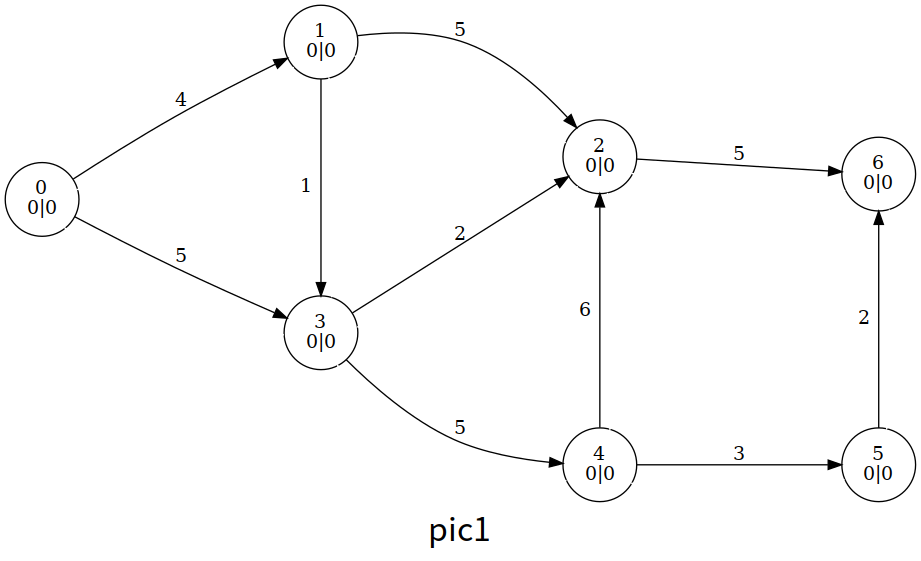
整个算法我们大致浏览一下过程,这里笔者使用的是一个暴力算法,即暴力扫描是否有溢出的结点,有就更新
最后的结果
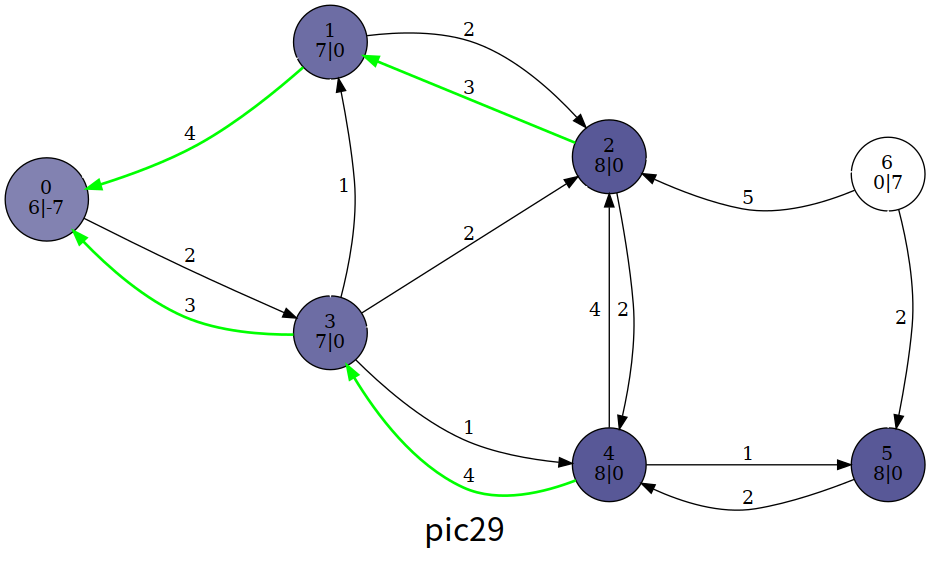
可以发现,最后的超额流一部分回到了
但是实际上论文3指出只处理高度小于
实现
HLPP 算法
最高标号预流推进算法(Highest Label Preflow Push)在上述通用的预流推送算法中,在每次选择结点时,都优先选择高度最高的溢出结点,其算法算法复杂度为
过程
具体地说,HLPP 算法过程如下:
- 初始化(基于预流推进算法);
- 选择溢出结点中高度最高的结点
- 如果
- 如果没有溢出的结点,算法结束。
一篇对最大流算法实际表现进行测试的论文4表明,实际上基于预流的算法,有相当一部分时间都花在了重贴标签这一步上。以下介绍两种来自论文5的能显著减少重贴标签次数的优化。
BFS 优化
HLPP 的上界为
在 BFS 的同时我们顺便检查图的连通性,排除无解的情况。
GAP 优化
HLPP 推送的条件是
以下的实现采取论文4中的实现方法,使用 B,其中 B[i] 中记录所有当前高度为
值得注意的是论文4中使用的桶是基于链表的栈,而 STL 中的 stack 默认的容器是 deque。经过简单的测试发现 vector,deque,list 在本题的实际运行过程中效率区别不大。
实现
感受一下运行过程
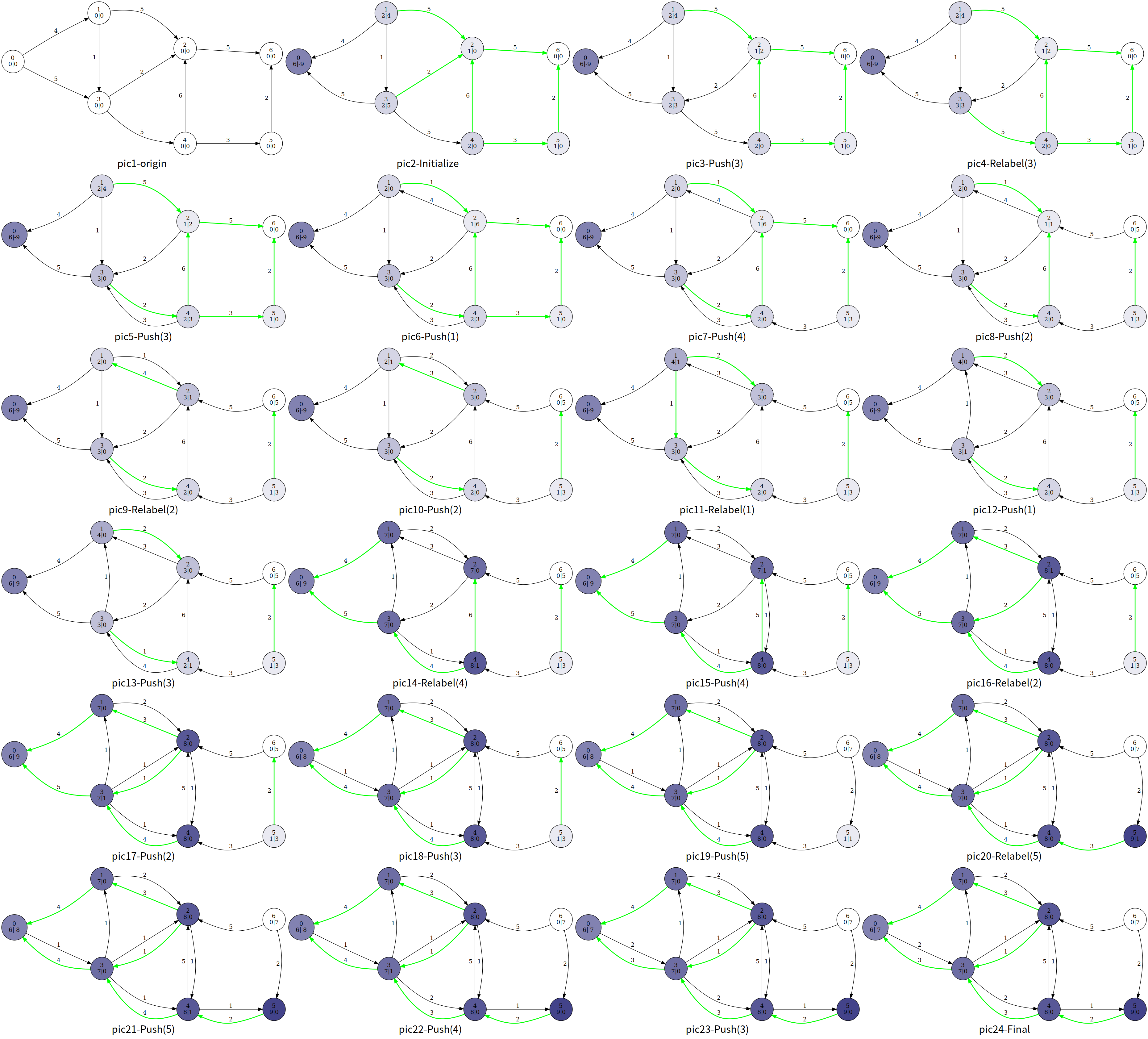
其中 pic13 到 pic14 执行了 Relabel(4),并进行了 GAP 优化。
脚注
Footnotes
-
英语文献中通常称为“active“。 ↩
-
在英语文献中,一个结点的高度通常被称为“distance label”。此处使用的“高度”这个术语源自算法导论中的相关章节。你可以在机械工业出版社算法导论(原书第 3 版)的 P432 脚注中找到这么做的理由。 ↩
-
Cherkassky B V, Goldberg A V. On implementing push-relabel method for the maximum flow problem[C]//International Conference on Integer Programming and Combinatorial Optimization. Springer, Berlin, Heidelberg, 1995: 157-171. ↩
-
Ahuja R K, Kodialam M, Mishra A K, et al. Computational investigations of maximum flow algorithms[J]. European Journal of Operational Research, 1997, 97(3): 509-542. ↩ ↩2 ↩3
-
Derigs U, Meier W. Implementing Goldberg's max-flow-algorithm—A computational investigation[J]. Zeitschrift für Operations Research, 1989, 33(6): 383-403. ↩
贡献者:@Nanarikom@Imple@queenwen@WenzelTian@Baoshuo@Ir1d@Danni@black_desk@Lin2602@qq2964@mgt@peterlits@Shuhao@Chrogeek@ouuan@Yaoyao@Wang@Trisolaris@frank@Xeonacid@orzcyand1317
本页面最近更新:2/3/2023, 12:00:00 AM,更新历史
发现错误?想一起完善? 在 GitHub 上编辑此页!
本页面的全部内容在 CC BY-SA 4.0 和 SATA 协议之条款下提供,附加条款亦可能应用